
进入 Apple silicon 时代以来,Mac 在性能方面的突飞猛进是大家有目共睹的,尤其是有了统一内存架构以后,CPU、GPU 以及 NPU 能够共享具备高带宽、低延迟的统一内存,让消费级的 Mac 电脑在运行本地 AI 模型时也能充分发挥硬件性能,参与到我们的日常生活与工作当中。
虽然云端模型的发展日新月异,但是本地模型依然有着不可替代的独特优势:对于普通用户而言,本地模型可以随时随地待命,不受网络质量制约,也能不被网络需求束缚,让更多人用上最新最先进的国内外大语言模型;对于企业用户来说,本地模型不仅有着能保护隐私安全的离线运行特性,还可以通过更灵活的自定义能力,定制自己专属的模型。
近日,我们就获得机会与 Exo Labs 的两位创始人有了一次简短的交流,听他们讲述了自己使用 Mac 进行本地 AI 模型应用的探索经历,还见到了他们即将发布的最新版本 exo 的功能演示。
Exo Labs 由多位来自牛津大学的工程师及研究人员共同创立于 2024 年,旨在普及人工智能技术,希望让更多人在任何地方都能更简单地运行和使用大语言模型。联合创始人 Alex 告诉我们,即使是在牛津大学这样的全球顶级学府,资源的分配和获取也是相当困难且缓慢的。如果想要向校方申请 GPU 集群进行本地模型研究,相关人员一次仅能申请一张显卡,整个申请过程可能需要长达数月之久。

正因如此,Alex 和伙伴们开始了自己最初的尝试,通过串联两台搭载 M3 Max 芯片的 MacBook Pro 组成集群,成功运行了参数量高达 4050 亿 (405B) 的 Llama 模型。虽然你应该能够想到结果,不论是在速度还是稳定性上,仅靠两台 MacBook Pro 运行如此复杂的模型都已经显得捉襟见肘。
不过,这次的尝试也让他们意识到了,这样的想法是完全可行的。随着 Apple silicon 架构的迭代,Exo Labs 团队也在不断优化 exo 的算法和框架,并在如今做好了新版的发布准备。
据介绍,如今 exo 不仅支持了多种主流的大语言模型——如 Llama、Mistral、Qwen 以及 DeepSeek 等等,并且支持动态模型拆分,在组成集群的多台设备中,exo 会根据每台设备的内存和带宽使用状况,自动将模型切分为多个部分,分配不同节点并切执行,从而让性能需求远超单台设备的本地模型能够顺利运行并实现快速响应。
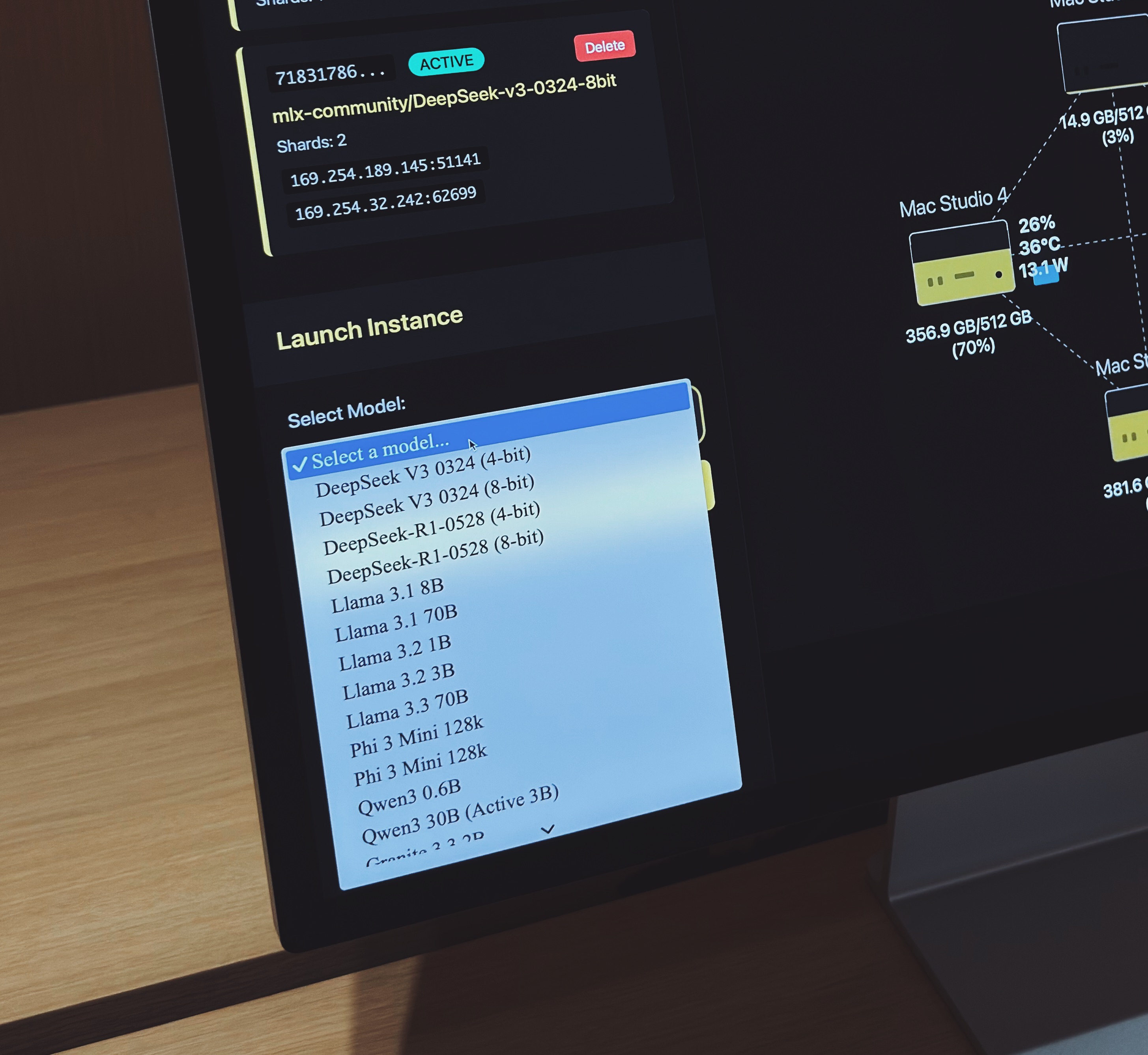
在现场演示中,Alex 通过四台搭载 M3 Ultra 芯片的顶配 Mac Studio 组成集群 (128 核 CPU、240 核 GPU、2TB 内存、~3.28TB/s 带宽),设备之间通过雷雳 5 线缆实现高速连接,向我们演示了 exo 的运行过程。

在这个集群中,exo 同时运行了 8-bit 量化版本的 DeepSeek-V3-0324 和 DeepSeek-R1-0528 两个本地模型,两个模型的总参数量高达约 1.36 万亿,所需内存接近 1.5TB。在如此高负载的工作场景之下,exo 不仅做到了同时并快速地向用户返回输出结果,还通过直观的可视化形式向我们展示了 exo 的动态分配能力,一览便能看清每台设备的内存使用情况、工作温度、耗电水平等等。
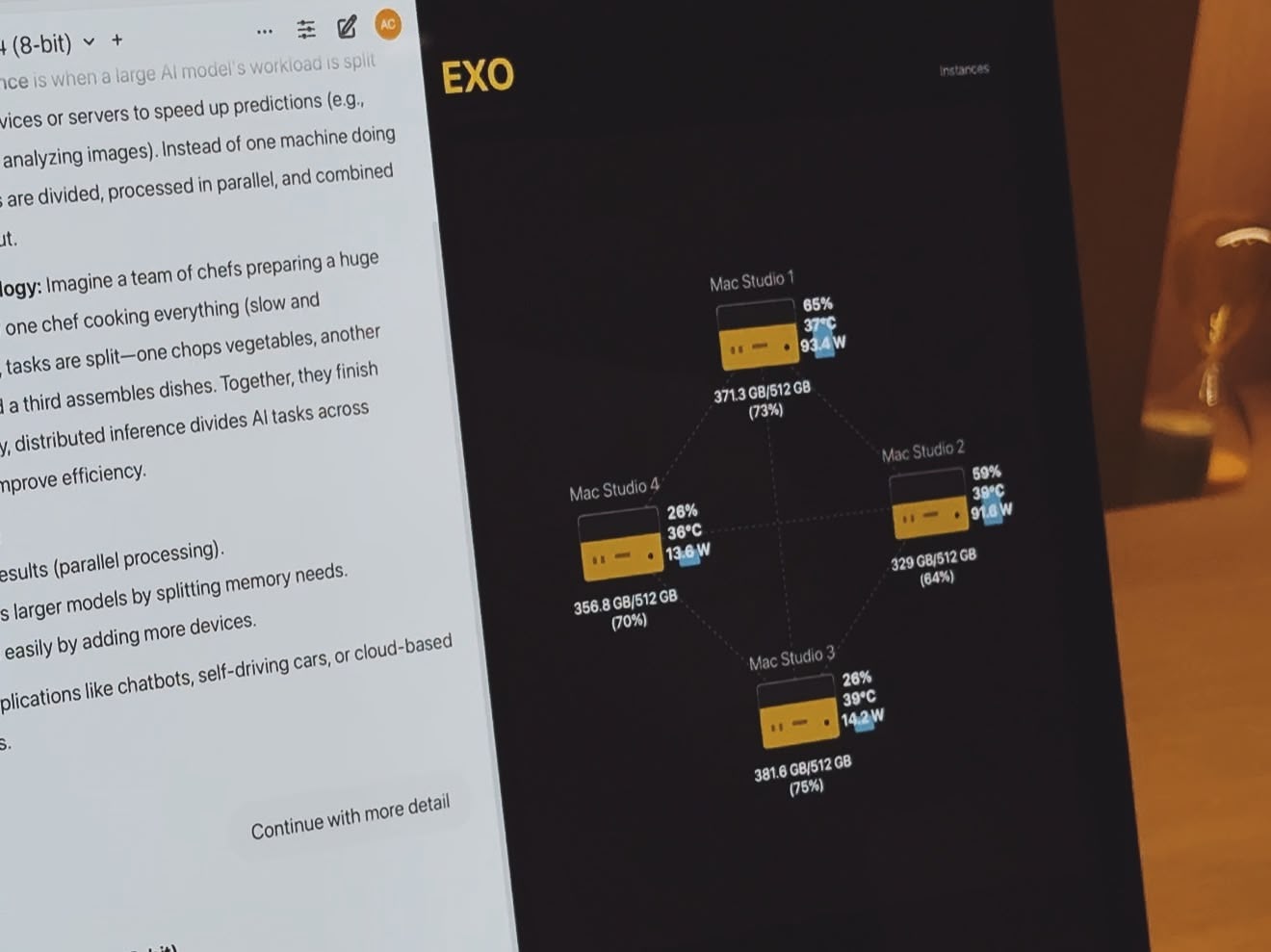
别看这四台 Mac 的售价已经高达 40 多万元人民币,要知道过去如果想通过传统硬件方案达到如此强大的性能表现,不仅需要采购售价高达百万级的硬件设施,相关设施对于空间如大小、散热等的复杂要求也是一个不小的考验。
Alex 还表示,exo 框架在开源之后获得了社区的热烈响应,并已有多家企业选择了 exo 在内部构建本地 AI 推理集群。值得一提的是,在 Global Energy Alliance for People and Planet 项目中,Exo Labs 仅仅通过几台老旧的智能手机与一台电脑设备连接,在非洲的一个偏远村庄中为当地运行本地大模型提供了支持,助力当地教育以及远程医疗服务。
最后,针对普通用户如何用好手中设备、善用 AI 能力,Alex 也给出了自己的看法。
虽然对于绝大部分用户而言,他们并没有采购价格如此高昂设备的能力以及需求,但依然不妨碍人人都能从本地模型中获益。
目前在 Mac 上,已经有如 Ollama、LM Studio、Open WebUI 等一众出色且易用的本地 LLM 部署和运行工具,让每个人都能轻松上手来自全球顶级科技公司的本地 AI 模型。这不仅能够让人人切实感受到技术的进步与发展,也能降低用户的试错成本,找到更加适合自己的 AI 模型。也得益于有像 Mac 这样愈发完善与强大的软硬件生态,AI 模型的使用门槛能够变得更低,运行速度能够变得越来越快。
富华优配-168股票配资网-最新股票配资app官网-配资知名证券配资门户提示:文章来自网络,不代表本站观点。







